Hi! I am an graduate student in Data Science at Harvard University. My research focus on aligning vision, language, and domain generalization in AI/ML applications, as well as in improving the reasoning, robustness, and fairness of large multimodal models. I’m fortunate to work with Peter Baile Chen from MIT CSAIL and Prof. Mengyu Wang from Harvard AI and Robotics Lab.
Previously, I graduated Summa Cum Laude from the University of California, San Diego (UCSD) with triple majors in B.S. in Data Science, B.S. in Applied Mathematics, and B.A. in Economics. I was advised by Prof. Zhuowen Tu and Prof. Hao Zhang for multimodality LLM and benchmarking during my undergraduate years. I’m the sole recipient of the 2024 Jeffrey B. Remmel Award for Academic Excellence for my contribution to the data science community at UCSD.
I am also an experienced full-stack developer, and my full-stack internship project is in the scope for L6 (Senior) SDEs according to the internal Amazon SDE role guide. I am on the job market now, please contact me for any opportunities!
Research
LLM Review: Enhancing Creative Writing via Blind Peer Review Feedback
@misc{li2026llmreviewenhancingcreative,
title={LLM Review: Enhancing Creative Writing via Blind Peer Review Feedback},
author={Weiyue Li and Mingxiao Song and Zhenda Shen and Dachuan Zhao and Yunfan Long and Yi Li and Yongce Li and Ruyi Yang and Mengyu Wang},
year={2026},
eprint={2601.08003},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.08003},
}
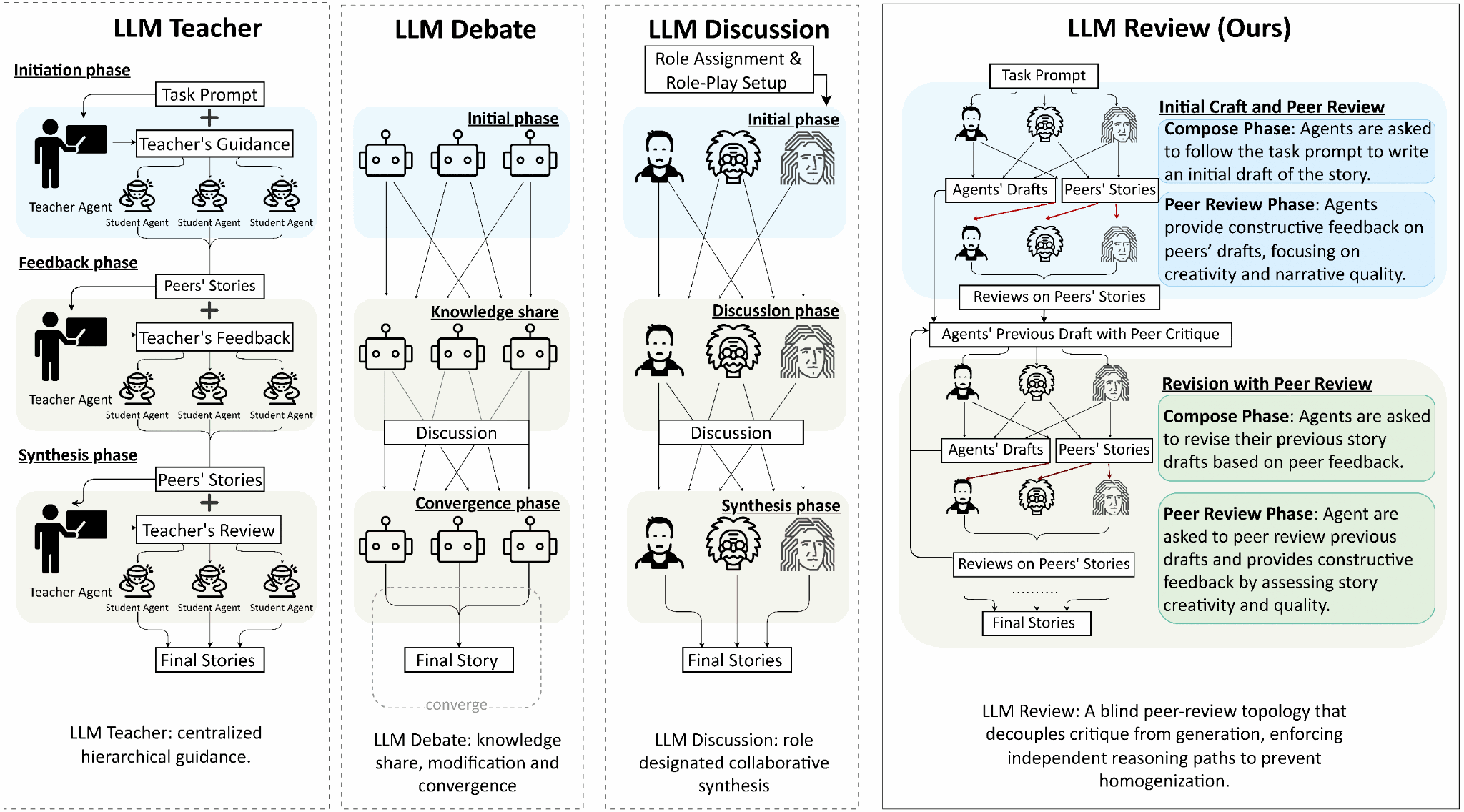
We introduce LLM Review, a peer-review-inspired creative-writing framework where multiple writer agents exchange targeted critiques with blind peer review feedback, reducing multi-agent homogenization while still benefiting from feedback. To evaluate creativity rigorously, we also propose SciFi-100, plus a unified evaluation stack combining LLM-as-a-judge, human annotation, and rule-based novelty metrics. Experiments show LLM Review consistently ranks best among multi-agent baselines on both rubric scores and novelty signals, and can let smaller models outperform larger single-agent baselines, suggesting interaction structure can substitute for scale.
Grading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale
Weiyue Li*, Minda Zhao*, Weixuan Dong*, Jiahui Cai*, Yuze Wei*, Michael Pocress, Yi Li, Wanyan Yuan, Xiaoyue Wang, Ruoyu Hou, Kaiyuan Lou, Wenqi Zeng, Yutong Yang, Yilun Du, Mengyu Wang under review paper
/ cite
@article{li2026grading,
title={Grading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale},
author={Li, Weiyue and Zhao, Minda and Dong, Weixuan and Cai, Jiahui and Wei, Yuze and Pocress, Michael and Li, Yi and Yuan, Wanyan and Wang, Xiaoyue and Hou, Ruoyu and others},
journal={arXiv preprint arXiv:2601.03444},
year={2026}
}
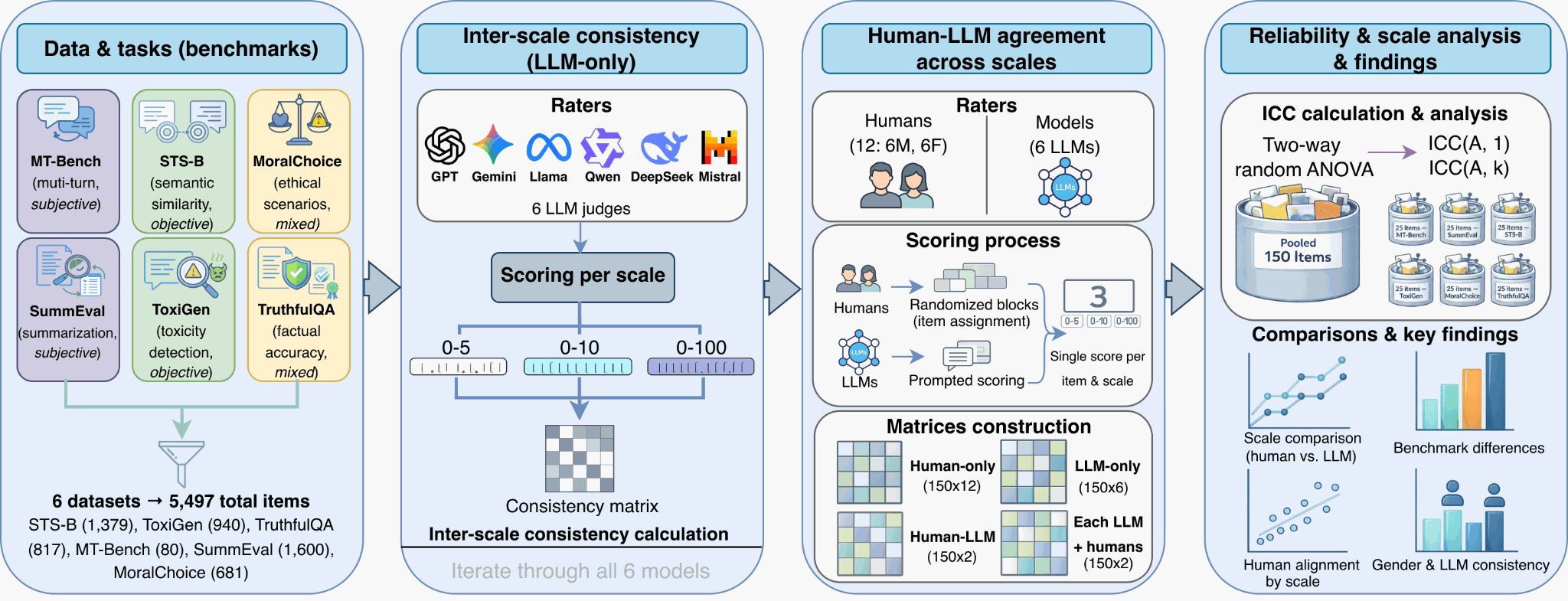
We study how the grading scale itself affects LLM-as-a-judge reliability and human-LLM alignment by collecting human + LLM ratings across three scales and six benchmarks spanning objective, subjective, and mixed tasks. Using intraclass correlation (ICC) for absolute agreement, we find that scale choice can substantially shift human-LLM alignment (even when within-panel reliability is high), and that a 0-5 scale yields the strongest overall alignment. We also show that pooled reliability can hide benchmark heterogeneity and reveals systematic subgroup alignment differences (e.g., across gender), motivating careful scale design and sub-level diagnostics in judge protocols.
Bias Is a Subspace, Not a Coordinate: A Geometric Rethinking of Post-hoc Debiasing in Vision-Language Models
@article{zhao2025bias,
title={Bias Is a Subspace, Not a Coordinate: A Geometric Rethinking of Post-hoc Debiasing in Vision-Language Models},
author={Zhao, Dachuan and Li, Weiyue and Shen, Zhenda and Qiu, Yushu and Xu, Bowen and Chen, Haoyu and Chen, Yongchao},
journal={arXiv preprint arXiv:2511.18123},
year={2025}
}
We rethink post-hoc debiasing in vision-language models, showing that “coordinate editing” methods can fail due to feature entanglement, cross-dataset dimension drift, and residual bias leakage, because bias is distributed over a low-dimensional subspace, not a few individual coordinates. Building on this geometric view, we propose Subspace Projection Debiasing (SPD): use INLP to identify the linearly-decodable bias subspace, project embeddings onto its orthogonal complement, and reinject a neutral mean to preserve semantic fidelity. Across zero-shot classification, text-to-image retrieval, and text-to-image generation, SPD reports more robust fairness gains (avg +18.5% over four fairness metrics) with minimal task-performance loss versus strong debiasing baselines.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
@article{chen2025concur,
title={CONCUR: A Framework for Continual Constrained and Unconstrained Routing},
author={Chen, Peter Baile and Li, Weiyue and Roth, Dan and Cafarella, Michael and Madden, Samuel and Andreas, Jacob},
journal={arXiv preprint arXiv:2512.09386},
year={2025}
}
We introduce CONCUR, a continual routing framework that maps each task to the best computation strategy (e.g., model + decoding method), supporting both unconstrained routing and budget-constrained routing. CONCUR uses a modular design, training one accuracy predictor and one cost predictor per strategy. This allows new strategies to be added by training only their respective predictors, which combine general-purpose and task-/strategy-specific representations to facilitate better decisions. Experiments on in- and out-of-distribution knowledge/reasoning tasks show improved end-to-end accuracy–cost tradeoffs over strong single-strategy and prior routing baselines, while reducing training overhead in continual settings.
The Necessity for Intervention Fidelity: Unintended Side Effects When Steering LLMs
@inproceedings{
raedler2025the,
title={The Necessity for Intervention Fidelity: Unintended Side Effects When Steering {LLM}s},
author={Jonas B Raedler and Weiyue Li and Alyssa Mia Taliotis and Manasvi Goyal and Siddharth Swaroop and Weiwei Pan},
booktitle={ICML 2025 Workshop on Reliable and Responsible Foundation Models},
year={2025},
url={https://openreview.net/forum?id=8nYQEGou3L}
}
We introduce intervention fidelity to evaluate whether activation steering changes only the targeted behavior or also causes unintended side effects. On Gemma-2-2B (base) vs Gemma-2-2B-IT (instruction-tuned), steering away from stereotypes on StereoSet increases anti-stereotypical outputs in both, but the base model improves by suppressing stereotypical answers, while the fine-tuned model’s gains largely come from suppressing unrelated outputs, which aggregate metrics can hide. We hypothesize this stems from fine-tuning increasing latent-space anisotropy, entangling behaviors and reducing steering precision.
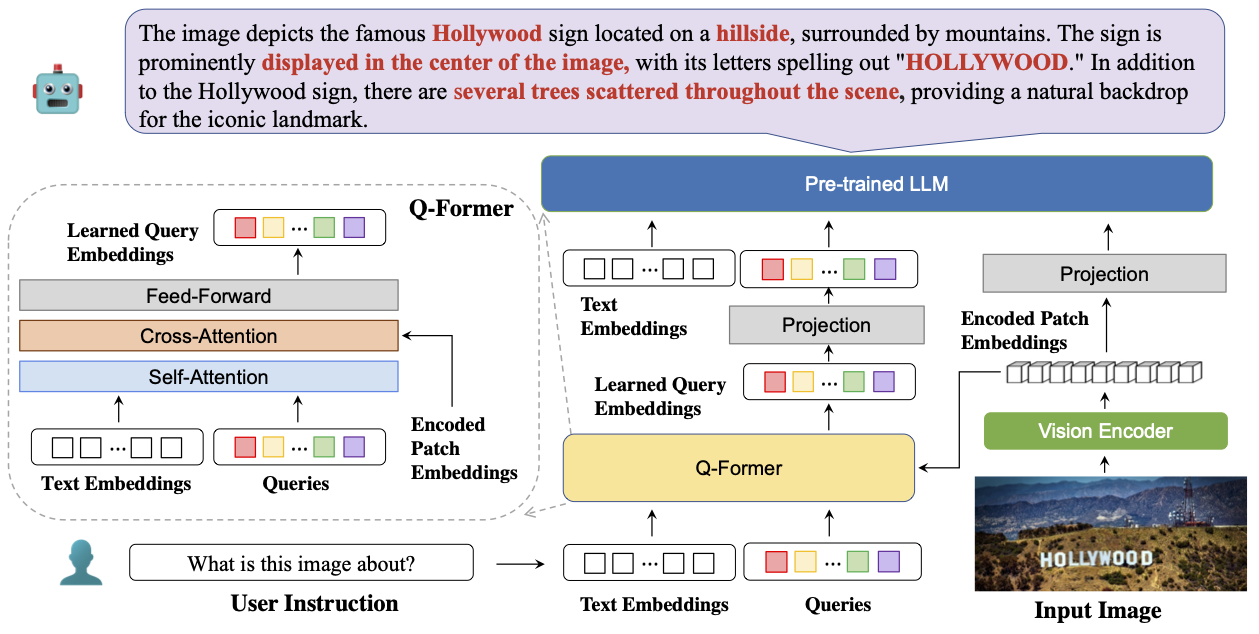
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions
@inproceedings{hu2024bliva,
title={Bliva: A simple multimodal llm for better handling of text-rich visual questions},
author={Hu, Wenbo and Xu, Yifan and Li, Yi and Li, Weiyue and Chen, Zeyuan and Tu, Zhuowen},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={3},
pages={2256--2264},
year={2024}
}
We introduce BLIVA, an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach ensures that the model captures intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence.
Selective Projects
SON: Enhancing Prompt Understanding of Diffusion Models with Large Language Models Guided Layouts
We introduce Spatial-Overlap-Numeracy-1K (SON-1K), a comprehensive benchmark for text-to-image generation. This benchmark comprises 1,000 complex prompts spanning three subtasks: spatial relationships, numeracy counts, and complex natural prompts. Alongside the benchmark, we propose several evaluation metrics to assess compliance with the prompts comprehensively. We also propose a new approach, the Language Model-Guided Diffusion++ (LMDpp), enhancing the performance of the novel two-stage Large Language Model (LLM)-grounded diffusion model pipeline (LMD).
Services
CVPR: Reviewer (2026)
Teaching
MLOps & LLMOps: Production AI Systems
Prof. Pavlos Protopapas
Harvard AC 215 FA25 website
This course provides a comprehensive understanding of the Deep Learning process with a strong emphasis on Machine Learning Operations (MLOps). It bridges the gap between model development and production operation, combining data science, data engineering, and software engineering practices. Students learn to build, deploy, and manage AI systems through an iterative process of development, testing, monitoring, and updating.
Planning and Learning Methods in AI
Prof. Stephanie Gil, Prof. Kiante Brantley
Harvard CS 1820 WI25
The course introduces the ideas and techniques underlying this exciting field, with the goal of teaching students to identify effective representations and approaches for a wide variety of computational tasks. Topics covered in this course are broadly divided into search and planning, optimization and games, and uncertainty and learning. Special attention is given to ethical considerations in AI and to applications that benefit society.
Introduction to Computational Linguistics and Natural-language Processing
Prof. Stuart Shieber
Harvard CS 1870 FA24
This course introduces the field of computational linguistics and natural language processing (NLP). It covers methods for analyzing and generating human language, including syntax, semantics, and pragmatics, as well as applications such as machine translation, information extraction, and dialogue systems.
This course will cover the basics about neural networks, as well as recent developments in deep learning including deep belief nets, convolutional neural networks, recurrent neural networks, long-short term memory, and reinforcement learning. We will study details of the deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification.
Introduction to Machine Learning
Prof. Edwin Solares
UCSD CSE 151A WI24
Broad introduction to machine learning. The topics include some topics in supervised learning, such as k-nearest neighbor classifiers, decision trees, boosting, and perceptrons; and topics in unsupervised learning, such as k-means and hierarchical clustering. In addition to the actual algorithms, the course focuses on the principles behind the algorithms.
Introduction to probabilistic models at the heart of modern artificial intelligence. Specific topics to be covered include probabilistic methods for reasoning and decision-making under uncertainty; inference and learning in Bayesian networks; prediction and planning in Markov decision processes; applications to intelligent systems, speech and natural language processing, information retrieval, and robotics.
The Practice and Application of Data Science (X3)
Prof. Tauhidur Rahman, Prof. Suraj Rampure
UCSD DSC 80 WI24, SP23, WI23 website /
evaluation
Students master the data science life-cycle and learn many of the fundamental principles and techniques of data science spanning algorithms, statistics, machine learning, visualization, and data systems.
DSC 40B, the second course in the sequence, introduces fundamental topics in combinatorics, graph theory, probability, and continuous and discrete algorithms with applications to data analysis.
Theoretical Foundations of Data Science I
Prof. Truong Son Hy and Prof. Mahdi Soleymani
UCSD DSC 40A FA22 website /
evaluation
DSC 40A will introduce fundamental topics in machine learning, statistics, and linear algebra with applications to data analysis.
Data Structures and Algorithms for Data Science
Prof. Soohyun Liao and Prof. Marina Langlois
UCSD DSC 30 SP22 website
Programming techniques including encapsulation, abstract data types, interfaces, algorithms and complexity, and data structures such as stacks, queues, priority queues, heaps, linked lists, binary trees, binary search trees, and hash tables with Java.
Programming and Basic Data Structures for Data Science (x4)
Programming techniques including recursion, higher-order functions, function composition, object-oriented programming, interpreters, classes, and simple data structures such as arrays, lists, and linked lists.
Principles of Data Science
Prof. Suraj Rampure and Prof. Janine Tiefenbruck and Prof. Rod Albuyeh
UCSD DSC 10 FA23 website
This first course in data science introduces students to data exploration, statistical inference, and prediction. It introduces the Python programming language as a tool for tabular data manipulation, visualization, and simulation. Through homework assignments and projects, students are given an opportunity to develop their analytical skills while working with real-world datasets from a variety of domains.
Econometrics (X2)
Prof. Gordon Dahl, Prof. Maria Candido
UCSD ECON 120B WI23, FA22 website /
evaluation
This course prepares students for empirical analysis in an academic or business setting. It covers the fundamentals of regression, including estimation and hypothesis testing in a univariate and multivariate framework. It presents ideas using the “potential outcomes” framework and makes the important distinction between prediction and causality. The course discusses reasons why estimators may be biased or inconsistent, and how both randomized experiments and natural experiments can be used to obtain causal estimates.
This course uses a variety of topics in mathematics to introduce the students to rigorous mathematical proof, emphasizing quantifiers, induction, negation, proof by contradiction, naive set theory, equivalence relations and epsilon-delta proofs.
Introduction to Differential Equations (X2)
Prof. Nandagopal Ramachandran, Prof. Ming Xiao
UCSD MATH 20D FA22*, SP21* website /
evaluation
Ordinary differential equations: exact, separable, and linear; constant coefficients, undetermined coefficients, variations of parameters. Systems. Series solutions. Laplace transforms. Techniques for engineering sciences. Computing symbolic and graphical solutions using MATLAB.
Calculus and Analytic Geometry for Science and Engineering
Prof. Emmanuel Vavalis
UCSD MATH 20C WI21* website
Vector geometry, vector functions and their derivatives. Partial differentiation. Maxima and minima. Double integration.
Calculus for Science and Engineering (X2)
Prof. Yucheng Tu, Prof. Yuming Zhang and Prof. Jacob Sterbenz
UCSD MATH 20A WI22, FA21 website /
evaluation
Foundations of differential and integral calculus of one variable. Functions, graphs, continuity, limits, derivative, tangent line. Applications with algebraic, exponential, logarithmic, and trigonometric functions. Introduction to the integral.