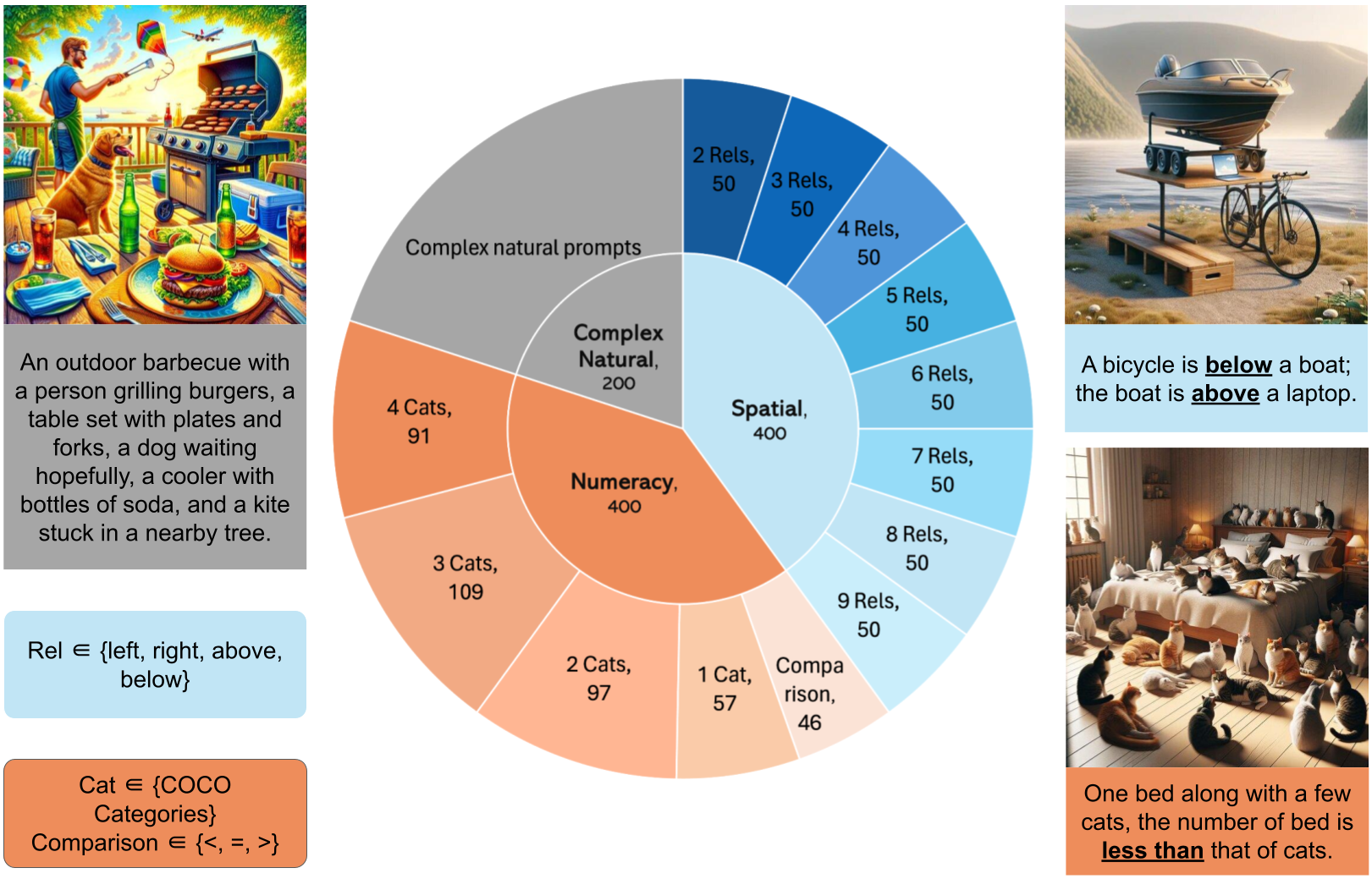
The recent development of text-to-image (T2I) models has unlocked numerous possibilities for content creation, particularly by offering inspiration to designers. However, current approaches often face challenges in accurately following prompts to generate images. These challenges include arranging non-overlapping objects in various spatial relationships and producing the correct number of desired objects, both of which are crucial for many design tasks. We introduce Spatial-Overlap-Numeracy-1K (SON-1K), a comprehensive benchmark for text-to-image generation. This benchmark comprises 1,000 complex prompts spanning three subtasks: spatial relationships, numeracy counts, and complex natural prompts. Alongside the benchmark, we propose several evaluation metrics to assess compliance with the prompts comprehensively. We also propose a new approach, the Language Model-Guided Diffusion++ (LMDpp), enhancing the performance of the novel two-stage Large Language Model (LLM)-grounded diffusion model pipeline (LMD). We report experimental results of previous major T2I models and our enhanced LMDpp, along with its baseline on SON-1K, and provide an analysis of our new metrics.
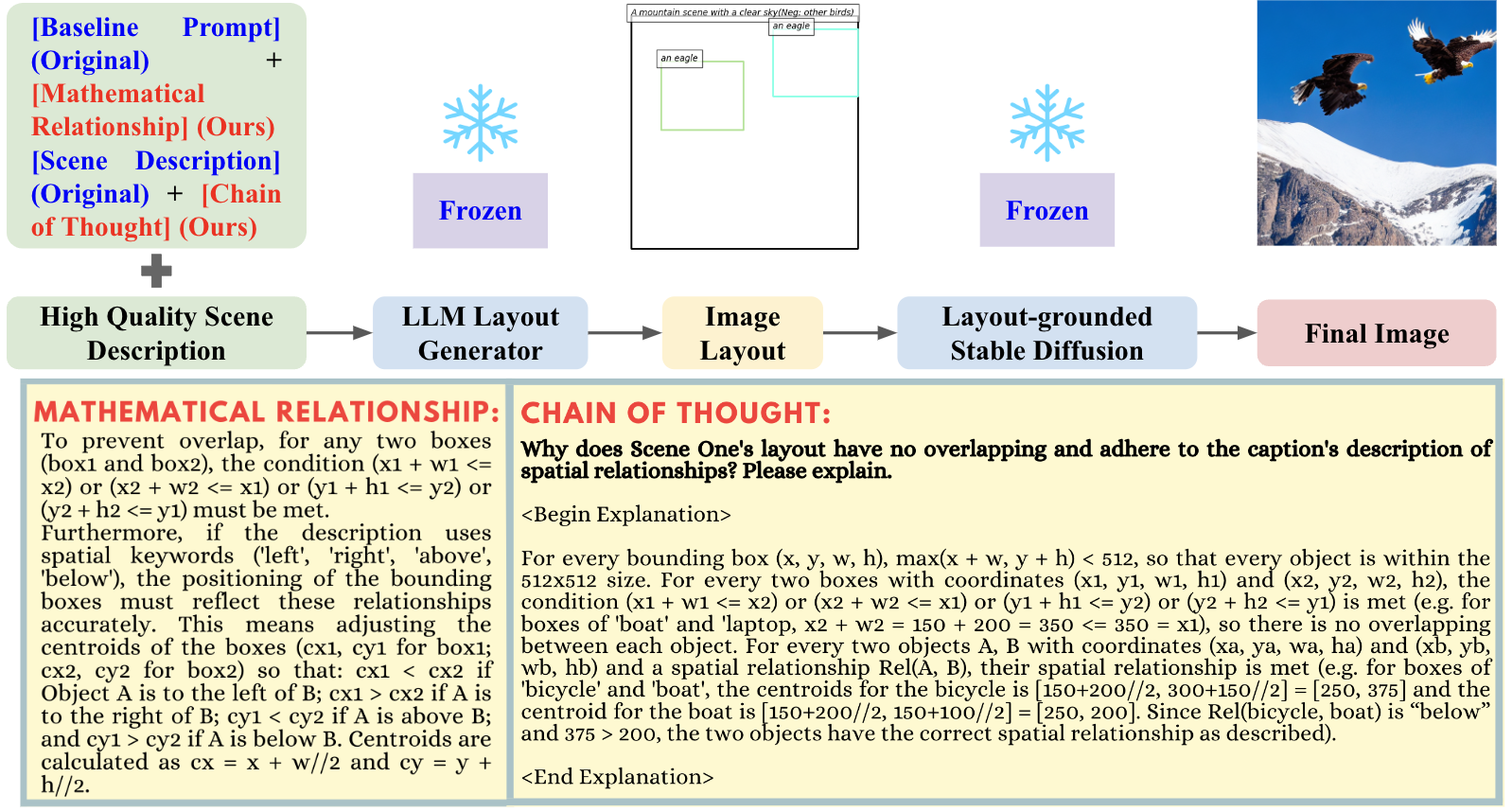
In stage one, our pipeline takes the scene description from the user and outputs the image layout based on our refined prompt, incorporated with mathematical relationships and chain of thought techniques. In stage two, the stable diffusion model generates the final image guided by the layout-grounded controller.
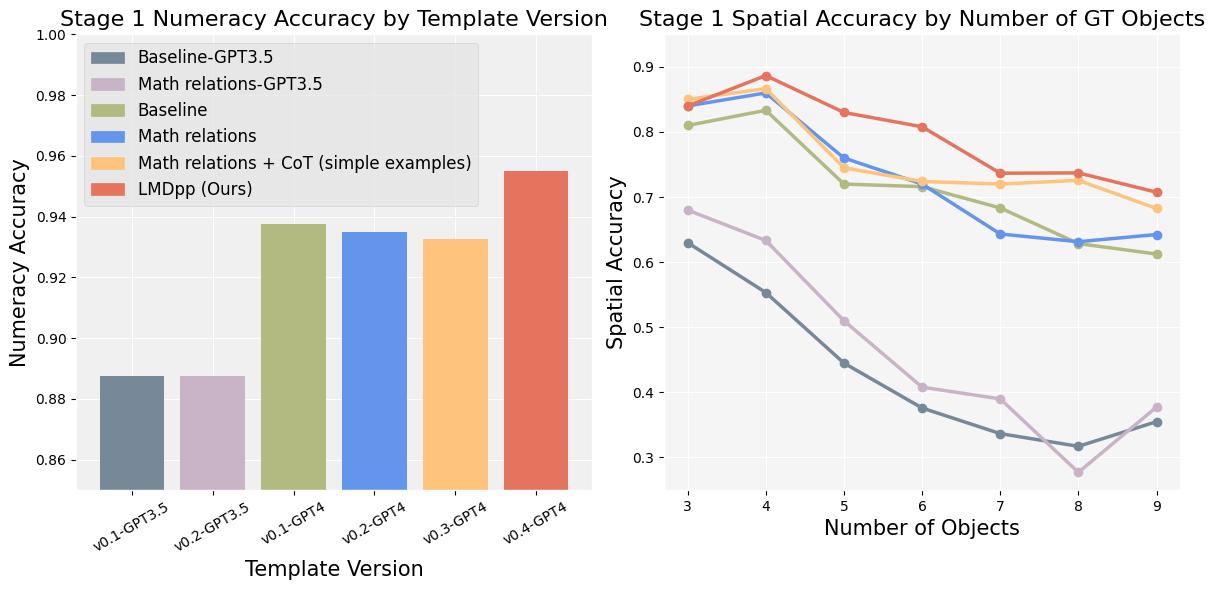
Comparison of numeracy and spatial accuracy among different templates of prompt
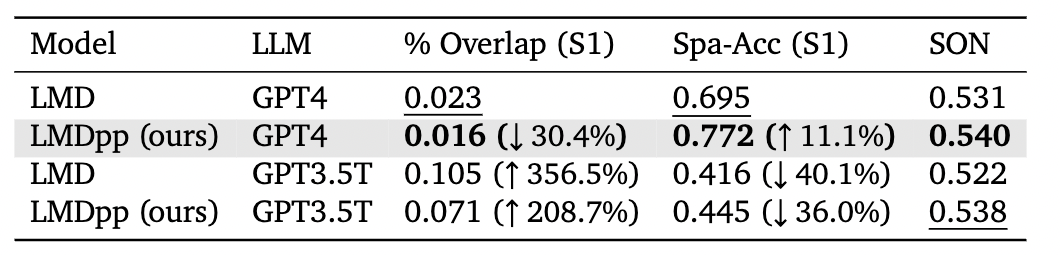
Table 1: Evaluation results for Spatial Tasks. % Overlap (S1) indicates the overlap rate for the layout image generated by the LLM in stage one. Spa-Acc (S1) indicates the spatial accuracy for stage one. SON indicates the values measured by our metric SON.

Table 2: Evaluation results for Numeracy Tasks. Num-Recall (S1) indicates the numeracy recall score for stage one. Num-Acc (S1) indicates the numeracy accuracy for stage one.
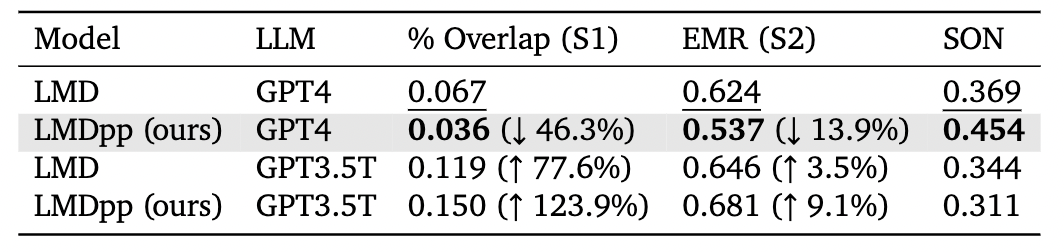
Table 3: Evaluation results for Complex Prompts. EMR (S2) indicates the EMR score of the final image generated by the diffusion model in stage two.
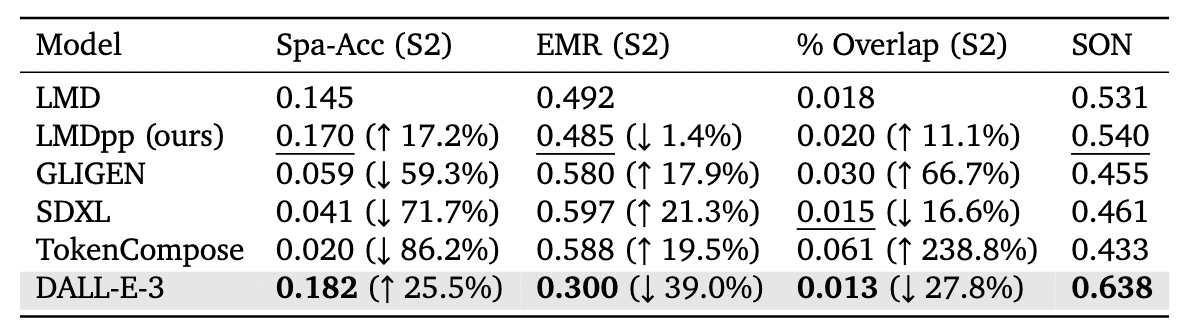
Table 4: Comparison between LMDpp with other T2I pipelines. Spa-Acc (S2) indicates the spatial accuracy for stage two. % Overlap (S2) indicates the overlap rate for stage two.
We introduce SON-1K, a comprehensive compositional text-to-image benchmark focusing on spatial relationships (400), numerical reasoning (400), and complex prompts (200), along with new metrics that consider object overlap in evaluation. These aim to address issues in compositional T2I generation and inspire designers in production. We provide the source code to facilitate the easy scaling of the dataset size, enabling a more comprehensive comparison between existing models. Additionally, we introduce a new method, LMDpp, which enhances the performance of the two-stage LMD pipeline through prompting techniques. Our study demonstrates that this enhanced two-stage technique surpasses all existing open-source T2I pipelines, while DALL-E-3 exhibits the best performance. This sheds light on future improvements, focusing on developing novel techniques for region control in diffusion models to generate more realistic and high-quality images, bringing us one step closer to achieving DALL-E-3's state-of-the-art performance.
We thank our mentor Dr. Hao Zhang for his guidance and support. 🙏
