
Research
|
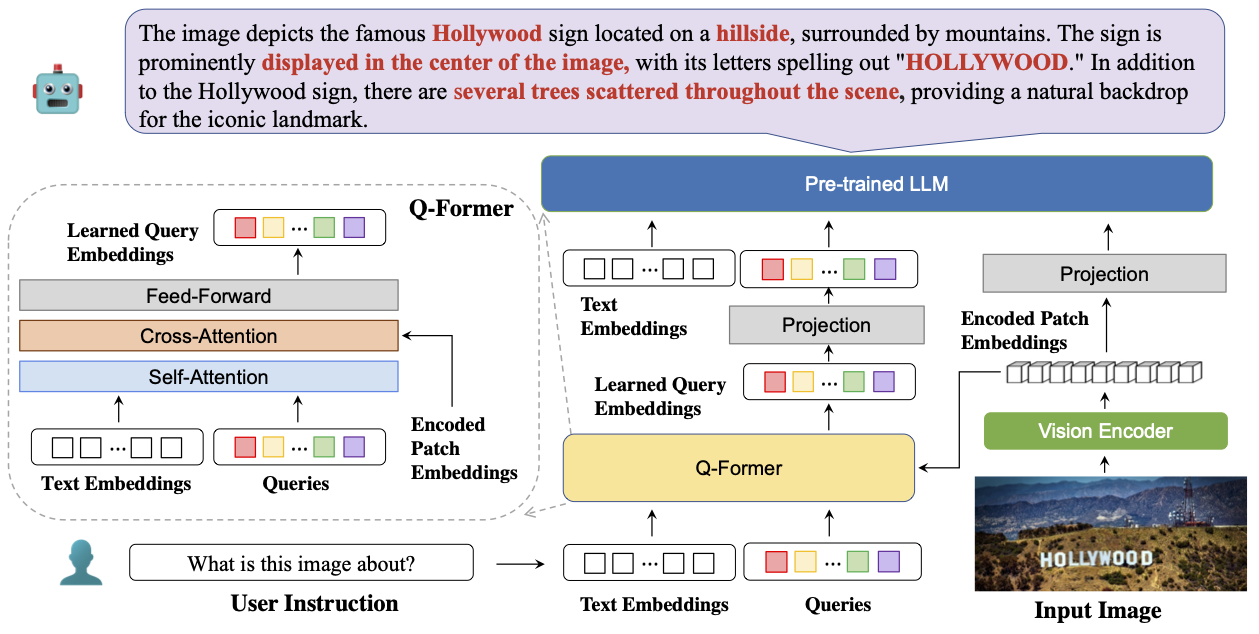
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual QuestionsWenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen, Zhuowen TuAAAI 2024 website / arxiv / code We introduce BLIVA, an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach ensures that the model captures intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence. |
Selective Projects
AI/ML

|
SON: Enhancing Prompt Understanding of Diffusion Models with Large Language Models Guided LayoutsWeiyue Li, Yi Li, Xiaoyue Wang, Hao Zhang2024 Outstanding Capstone Project Award website / report / code We introduce Spatial-Overlap-Numeracy-1K (SON-1K), a comprehensive benchmark for text-to-image generation. This benchmark comprises 1,000 complex prompts spanning three subtasks: spatial relationships, numeracy counts, and complex natural prompts. Alongside the benchmark, we propose several evaluation metrics to assess compliance with the prompts comprehensively. We also propose a new approach, the Language Model-Guided Diffusion++ (LMDpp), enhancing the performance of the novel two-stage Large Language Model (LLM)-grounded diffusion model pipeline (LMD). |
|
Training Language Models on a Computational BudgetWeiyue Li, Yi Li, Xiaoyue Wangreport / code We introduce a technical report that outlines our methodology for calculating model parameters, training FLOPs (floating-point operations), and memory costs. Based on these calculations and adhering to the Chinchilla scaling law, we design three model configurations—large, medium, and small—to align with our computed computational budget. All models are trained using the SlimPajama-6B benchmark on eight NVIDIA A6000 48GB GPUs. We achieve cross-entropy losses for each model size: 2.339 for large, 2.165 for medium, and 2.091 for small. Lastly, we conduct an inference task using our most effective model. |
|
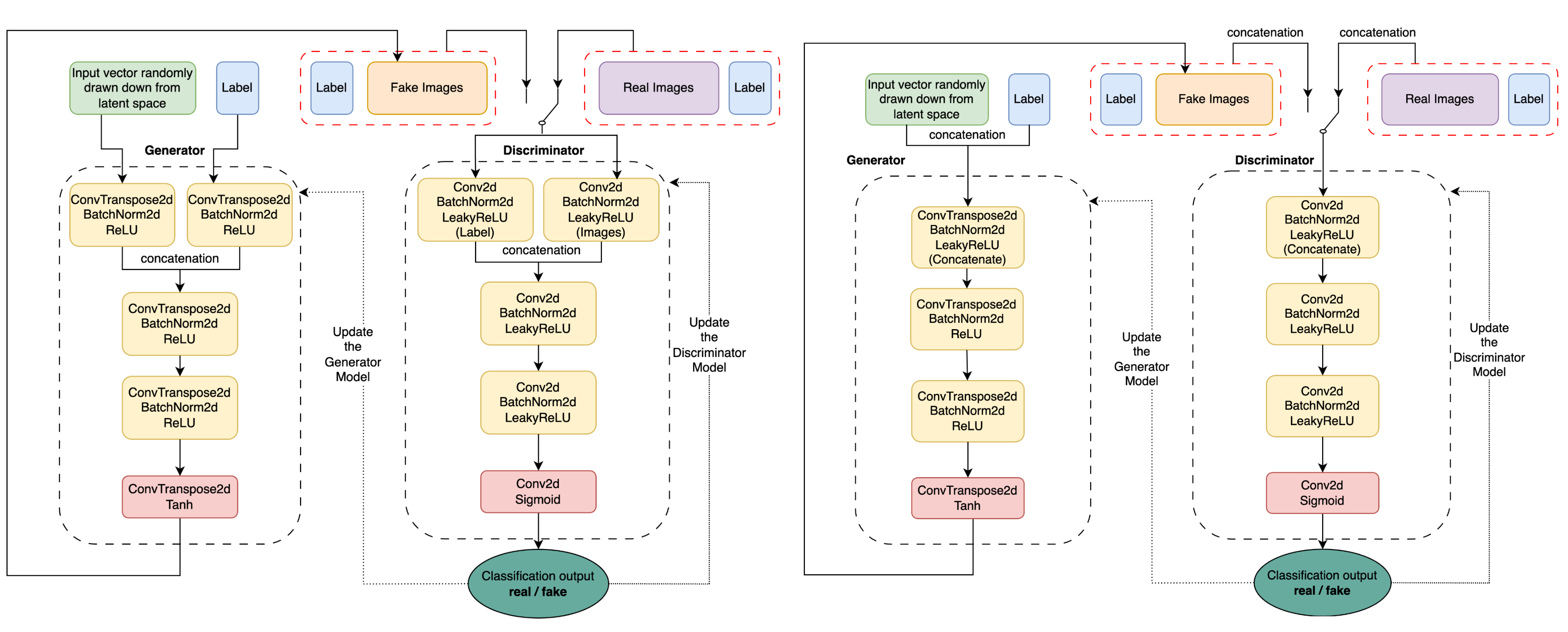
Generative Vision: Image Synthesis with Conditional DCGANsWeiyue Li, Charles Yereport / code Our project proposes two architectures with early or late concatenations to improve the performance of the original cGANs paper's architecture. The project involves training cDCGANs and cGANs on large-scale labeled datasets, where the models are conditioned on auxiliary information such as class labels. We also employ various metrics to evaluate the performance, and the results show that our cDCGANs model validates its effectiveness in generating high-quality and realistic images. |
|
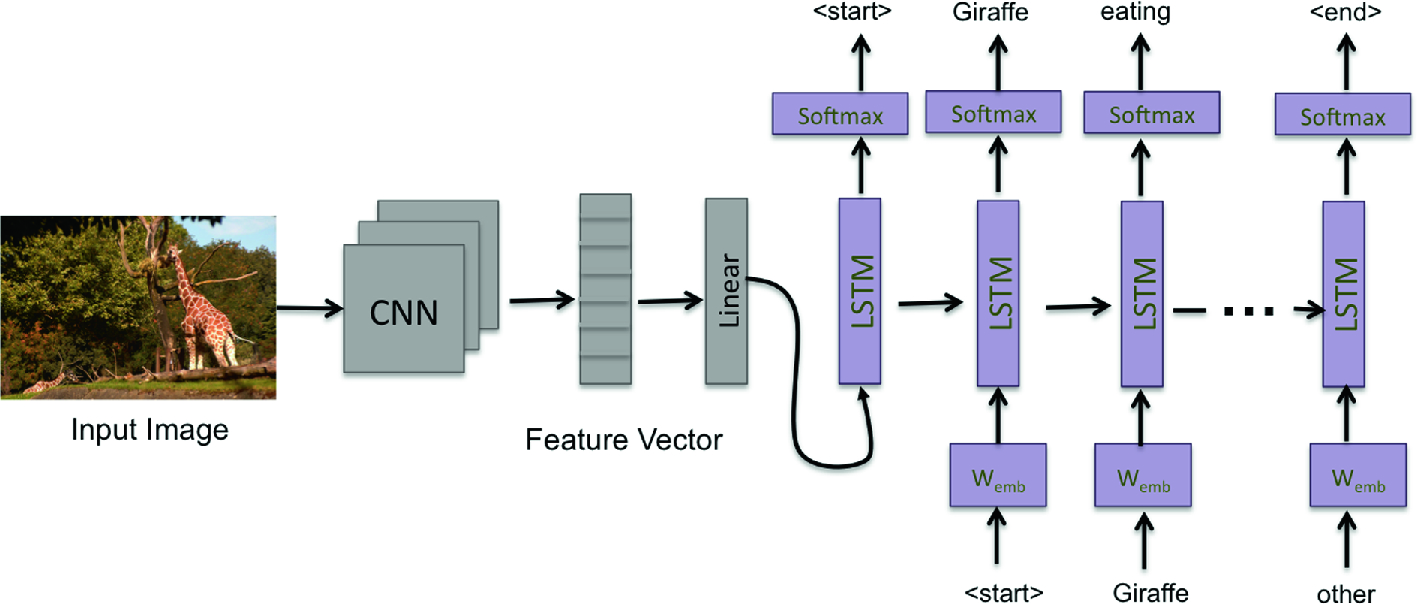
Automatic Image AnnotationYi Li, Weiyue Li, Linghang Kong, Yibo Wei, Shuangmu Wureport / code In this project, we trained an algorithm to caption input images. This required the algorithm to identify objects in the images and match them to a corpus of text. We used PyTorch to implement multiple Recurrent Neural Network (RNN) models, including LSTM, Vanilla RNN, and a custom model (Architecture 2), to generate captions for the images in our dataset, specifically the well-known COCO Image Captioning Task. |
|
Recipe Recommender SystemWeiyue Li, Yi Li, Xiaoyue Wang, Ruoyu Houreport / code In this project, we first performed exploratory data analysis on datasets from food.com. We then implemented various types of recommendation system models to recommend recipes to users, predict ratings based on sentiment analysis, and predict recipe categories. |
Data Analysis
|
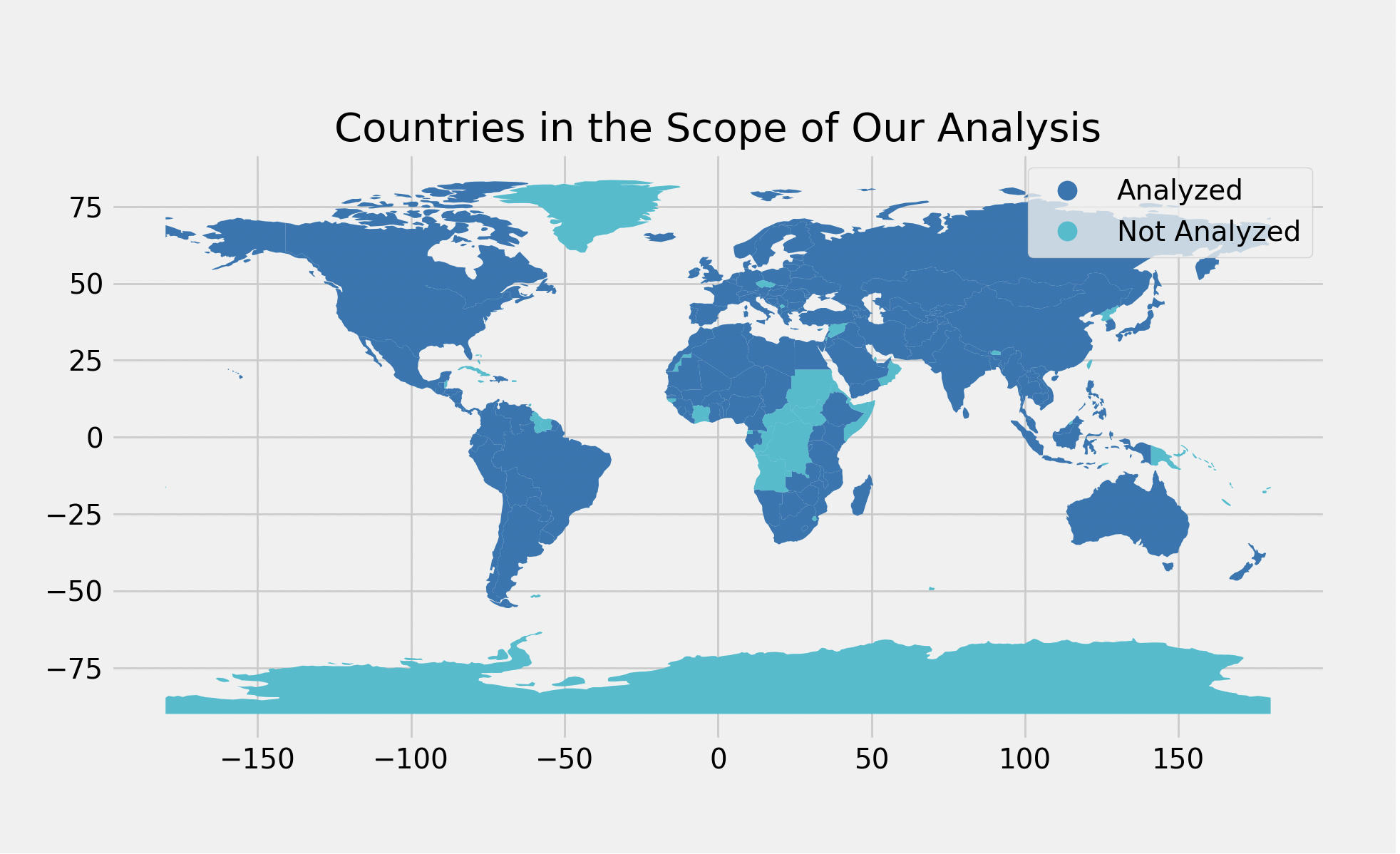
Taming COVID-19 Statistics to Reflect Happiness Score MetricsZirui Wang, Weiyue Li, Luning Yang, Yuru Zhoureport / code In this project, we make use of the vaccination/death data by country, and explore the relationship between the set of {nation-wide onset date of vaccination, average new vaccination/death rate across different time spans}, and various metrics of happiness score in 2021. In particular, we are trying to figure out to what extent our independent varibles, namely all COVID-19 related data, are correlated to these metrics (i.e. social support, healthy life expectancy, perception of corruption, and generosity) of happiness scores. |
Data Visualization
|
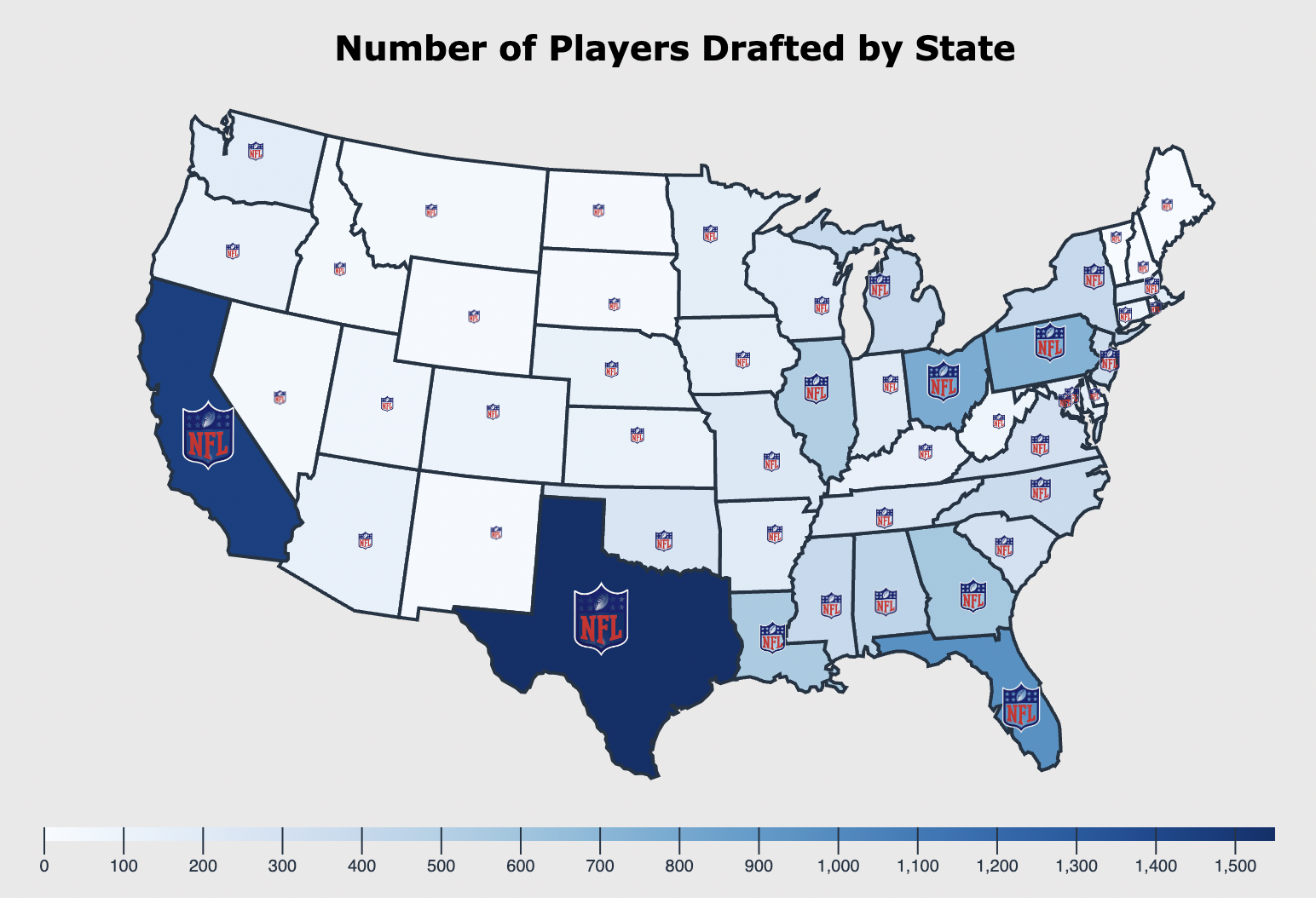
NFL Players VisualizationWeiyue Lireport / code In this project, I have developed an interactive dashboard aimed at providing high school varsity football players with a more comprehensive understanding of the critical considerations involved in becoming NFL players. In addition to drawing conclusions from past data, I have also made data-driven suggestions for young players. The primary objective of this project was to practice and enhance my skills in JavaScript, D3.js, and HTML. |
Econometrics
|
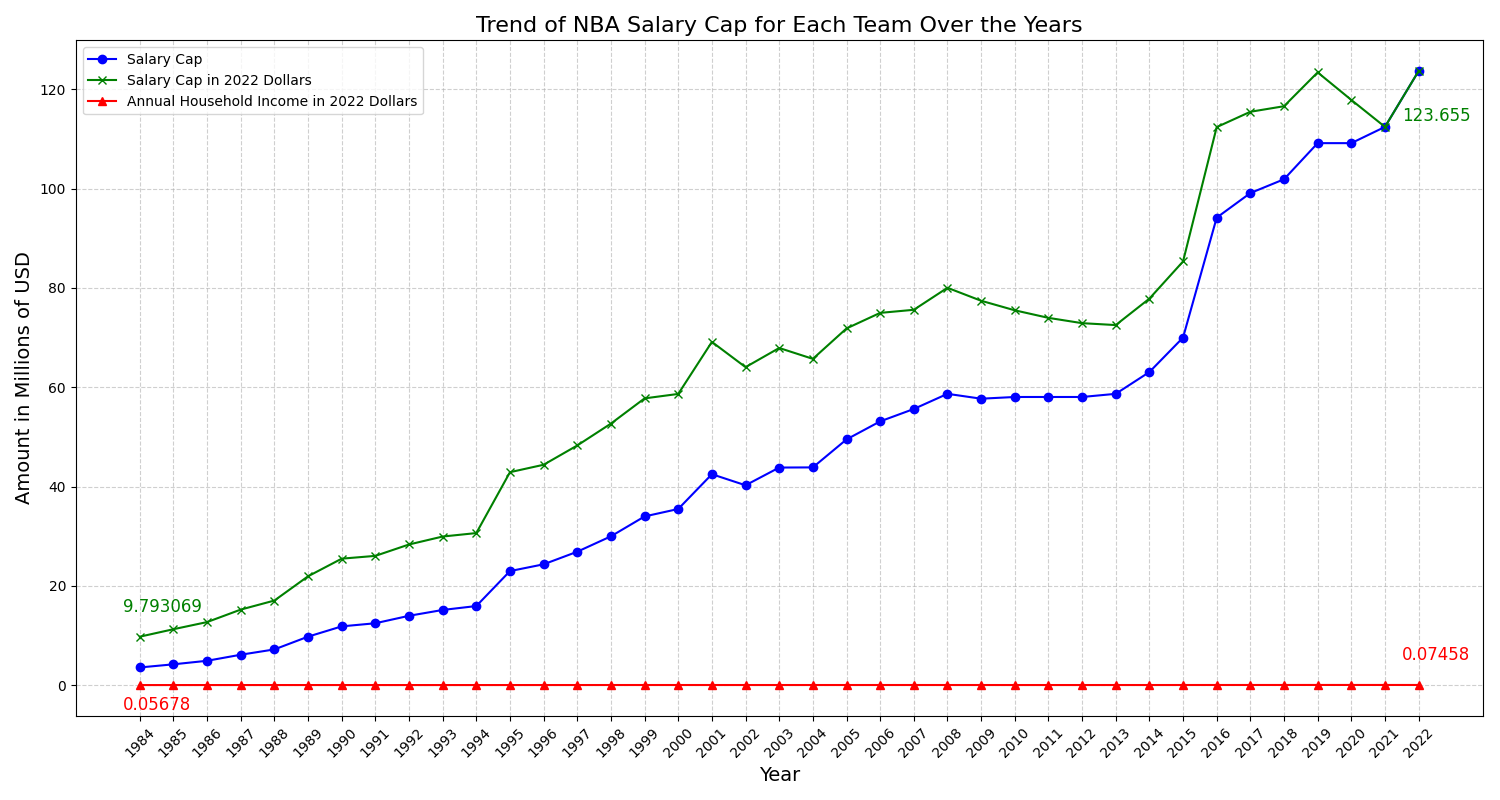
NBA Player Salaries: Are 3-Pointers Making Differences?Weiyue Lireport / code This project examines the influence of 3-point shooting abilities on NBA players' salaries. We delve into whether excelling in 3-pointers correlates with higher salaries, considering various factors and statistical models. |
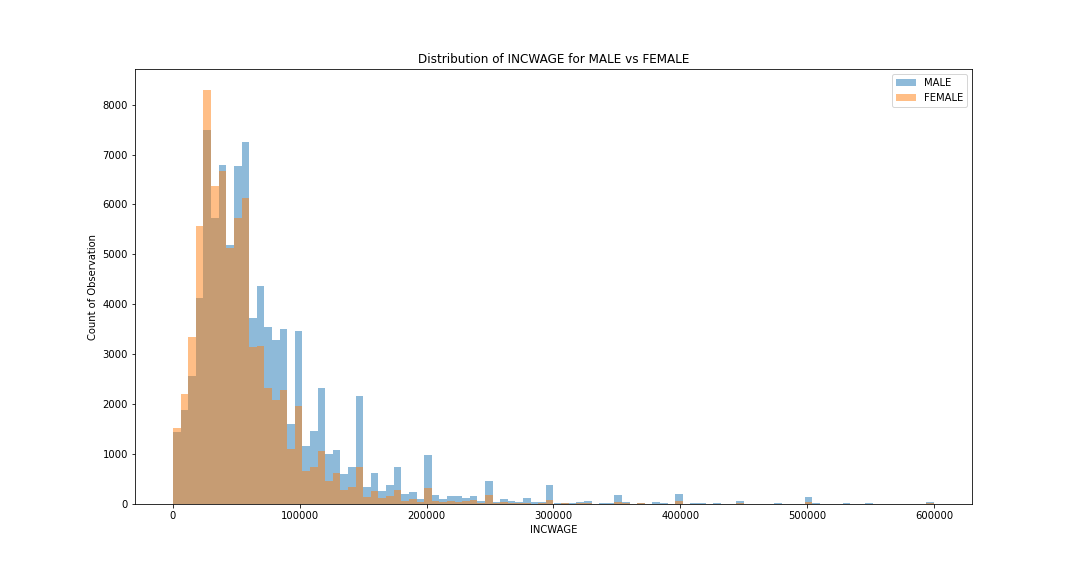
|
Occupation in Wage Gap Between SexJiahui Cai, Weiyue Lireport / code In this project, we perform a regression analysis to the IPUMS CPS data. In particular, we divide occupations into male-dominated, female-dominated, and equal-dominated and perform a regression analysis to aim for drawing a causal inference of occupation on the wage gap between sex during the COVID and post-COVID era. |
Others
This is a website that contains works I have done for the 3-quarter sequence of first-year Japanese courses I have taken in my freshman year of college. In case you are interested in taking the sequence, here are the topics you will work on.
This page captures all of my work from EDS 124BR (Teach Computational Thinking). I think this course has helped me to become better at my job as a teaching assistant.
Leave a comment